独自のテキスト検索式を直接作成したり、テキスト エンティティを使用してそれを作成することもできます。テキスト エンティティは、定義済みまたはユーザー定義のコンポーネント、またはテキスト検索式に含めることが可能な構成要素です。
テキスト エンティティには次の 3 つのタイプがあります。
-
 定義済みのエンティティ
定義済みのエンティティ
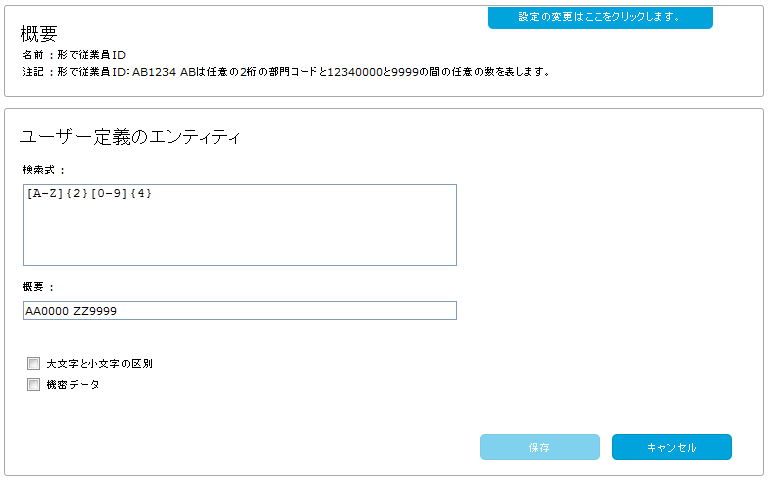
定義済みのエンティティは、よく使用される、設定済みの標準のテキスト検索式です。たとえば、定義済みのエンティティは、クレジットカード番号または異なる地域のID番号(IDカード、運転免許証、パスポート、日本のマイナンバー)と一致させることができます。定義済みのエンティティは固定パターンであり、編集できません。
-
ユーザー定義のエンティティ
独自の再利用可能なテキスト エンティティを設定できます。これらのユーザー定義エンティティはリストに表示され、テキスト検索式で利用できます。
-
テキスト検索式修飾子
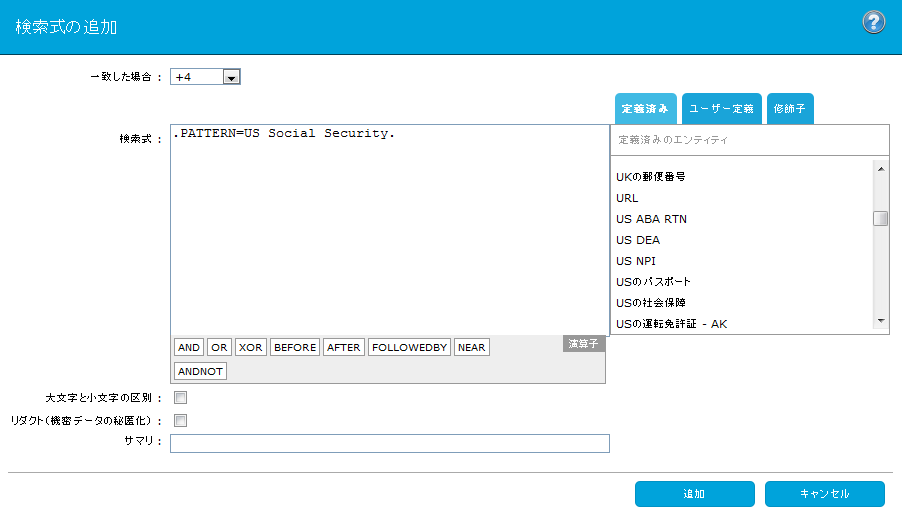
テキスト検索式修飾子は、検出を行う特定の値であり、一般的なテキスト パターンではありません。たとえば、リダクトやブロックを行う、特定の ID 番号のリストを作成できます。そのリストを修飾子のセットとしてインポートして、テキスト検索式で使用できます。詳細については、「テキスト検索式修飾子」を参照してください。
-
区切り文字と単語のマッチング
プレーンテキストのテキスト検索式を作成する場合、
検索式に指定されていない場合、テキスト内の区切り文字は無視されます。単語の一部は一致とみなされません。
検索式 テキスト 一致? here and there here and there はい here and there here, and there はい here and there here-and-there はい don't don't はい dont don't いいえ don't dont いいえ don t don't はい don't don t いいえ butt butter いいえ swear menswear いいえ pig spigot いいえ -
一致した場合
テキスト検索式の重みスコア。この値によって、検索式がセキュリティ ポリシーに及ぼす影響が決定されます。
例: 重み付きのテキスト検索式
Cakes and Pastries という名前のテキスト検索式の検出コンテンツ規則は、菓子製品の名前を検出するための規則です。
検索式リスト (下記) には、重みの合計として 10 の [しきい値] が設定されています。
各製品のカスタム検索式は次のように追加します。各検索式に [重み] を設定します。
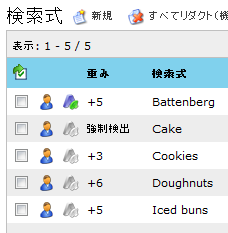
通信に検索式 "ドーナツ" と "アイス" が含まれる場合、重みの合計 (6+5=11) がしきい値 (10) を上回り、コンテンツ規則がトリガされます。ただし、"アイス" と "クッキー" が検出された場合、重みの合計 (5+3=8) は、コンテンツ規則をトリガするには不十分です。
[強制検出] の重みが設定された検索式 (この例の "Cake" など) では、しきい値に関係なく常にコンテンツ規則がトリガされます。
また、検索式リストは、検索式の重みをメッセージの各部分で 1 回のみカウントするように設定できます。たとえば、Cookies, Cookies, Cookies!" という件名を持つメッセージの場合、このオプションが有効になっていると、重みの合計として +3 が加算されます。 -
演算子
論理演算子を使って、テキスト検索式を作成できます。演算子は、キーワード、フレーズ、またはテキスト エンティティの間に置く必要があります。

演算子 説明 AND 両方のキーワードまたはフレーズが存在する必要があります。 OR 一方または両方のキーワードまたはフレーズが存在する必要があります。 XOR 両方ではなく一方のキーワードまたはフレーズが存在する必要があります。 BEFORE 両方のキーワードまたはフレーズが存在する必要があり、なおかつ演算子の前のキーワードまたはフレーズが、演算子の後のキーワードまたはフレーズより先に出現する必要があります。 AFTER 両方のキーワードまたはフレーズが存在する必要があり、なおかつ演算子の前のキーワードまたはフレーズが、演算子の後のキーワードまたはフレーズより後に出現する必要があります。 FOLLOWEDBY=x 両方のキーワードまたはフレーズが存在する必要があり、なおかつ演算子の後のキーワードまたはフレーズが、演算子の前のキーワードまたはフレーズの x ワード以内に存在する必要があります。 NEAR 両方のキーワードまたはフレーズが存在する必要があり、なおかつこれらのキーワードまたはフレーズがお互いに 10 ワード以内に存在する必要があります。検索式は、どちらの順序で出現してもかまいません。 ANDNOT 演算子の前のキーワードまたはフレーズが存在する必要があり、なおかつ演算子の後のキーワードまたはフレーズが存在してはなりません。 複数の演算子を使う場合、かっこを使って論理演算の動作が正しくなるようにします。 -
大文字と小文字の区別
[大文字と小文字の区別] チェック ボックスは、テキスト検索式に大文字と小文字を区別するマッチングを適用します。
-
リダクト(機密データの秘匿化)
テキスト検索式を [リダクト] に設定して、リダクション可能にできます。
可能であれば、リダクション可能なテキスト検索式には、[強制検出] の重みを使用します。
-
サマリ
[概要] ボックスは、テキスト検索式に関する追加の注記を表示するために使用できます。最大で 180 文字まで入力できます。
 [編集]
[編集] [新規]
[新規]